4.2. Working with Strings and Lists¶
Data wrangling involves transforming data from some raw form to another more
useful form. Often this raw form is text saved in a text file, which
corresponds to the Python string data structure. In this section, we will
illustrate the process of converting and transforming textual data list
comprehensions and the split, join and format methods.
4.2.1. Character classification¶
It is often helpful to examine a character and test whether it is upper- or
lowercase, or whether it is a character or a digit. The string module
provides several constants that are useful for these purposes. One of these,
string.digits is equivalent to “0123456789”. It can be used to check if a
character is a digit using the in operator.
The string string.ascii_lowercase contains all of the ascii letters that the
system considers to be lowercase. Similarly, string.ascii_uppercase contains
all of the uppercase letters. string.punctuation comprises all the
characters considered to be punctuation. Try the following and see what you get.
In [1]: import string
In [2]: string.ascii_lowercase
Out[2]: 'abcdefghijklmnopqrstuvwxyz'
In [3]: string.ascii_uppercase
�������������������������������������Out[3]: 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
In [4]: string.digits
��������������������������������������������������������������������������Out[4]: '0123456789'
In [5]: string.punctuation
�����������������������������������������������������������������������������������������������Out[5]: '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
For more information consult the string module documentation (see Global
Module Index).
4.2.2. More on working with strings and lists¶
There are two common patterns that are applied when processing strings. Both
patterns start by using the string split method to split the string into a
list of strings. Then a list comprehension is used to transform the list of
strings and some post-processing is applied.
The first pattern is used when computing statistics about a string. The following figure illustrates this process.
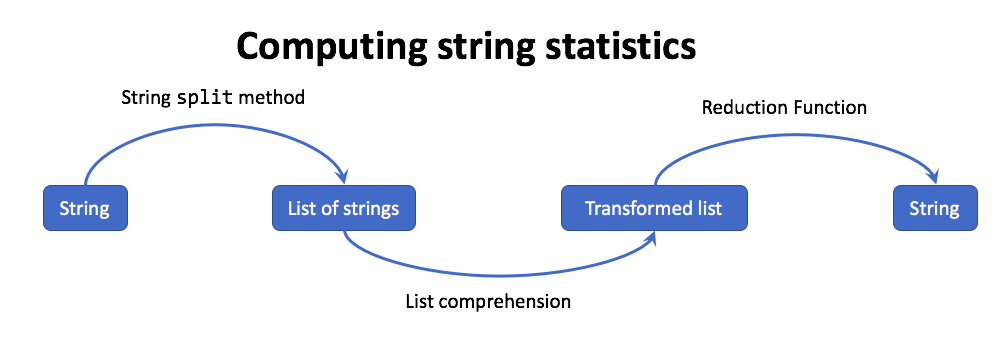
Let’s start by counting the number of vowels in a word.
In [1]: vowels = "aeiou"
In [2]: word = "Mississippi"
In [3]: num_vowels = len([ch for ch in word if ch.lower() in vowels])
In [4]: num_vowels
Out[4]: 4
We generalized this expression with lambda expression.
In [5]: num_vowels = lambda word: len([ch for ch in word if ch.lower() in vowels])
In [6]: num_vowels("Minnesota")
Out[6]: 4
This illustrates an important pattern when working with expression.
- Work with an example until an expression is developed to accomplish a task.
- Package that expression in a function.
- Update your example and move to the next task.
Task: Find the average number of vowels in the words in a string
Next, we will use this function to compute the average number of words in a sentence. We start by going through the process step-by-step.
First, we need to remove punctuation so that it doesn’t add artificial length to the strings. We will accomplish this be removing any punctuation (determined by importing punctuation from string and checking each character.)
In [7]: from string import punctuation
In [8]: punctuation
Out[8]: '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
In [9]: quote = '''I know something ain't right.
...: Sweetie, we're crooks. If everything were right, we'd be in jail.'''
...:
In [10]: characters_no_punc = [ch.lower() for ch in quote if ch not in punctuation]
In [11]: characters_no_punc[:10]
Out[11]: ['i', ' ', 'k', 'n', 'o', 'w', ' ', 's', 'o', 'm']
Notice that this returns a list of (lower case) characters, skipping the
punctuations marks. To make this back into a string, we join the strings in
the list back together.
In [12]: str_no_punc = "".join(characters_no_punc)
In [13]: str_no_punc
Out[13]: 'i know something aint right\n sweetie were crooks if everything were right wed be in jail'
Let’s combine these two steps into one expression
In [14]: s_no_punc = "".join([ch.lower() for ch in quote if ch not in punctuation])
In [15]: s_no_punc
Out[15]: 'i know something aint right\n sweetie were crooks if everything were right wed be in jail'
and turn this expression into a general function by replacing quote with a
most general variable (S for string.) This function is tested on the quote
to make sure it still works.
In [16]: remove_punc = lambda S: "".join([ch.lower() for ch in S if ch not in punctuation])
In [17]: s_no_punc = remove_punc(quote)
Since we are interested in the words in the string, we split by whitespace
(default action of split).
In [18]: words = s_no_punc.split()
In [19]: words
Out[19]:
['i',
'know',
'something',
'aint',
'right',
'sweetie',
'were',
'crooks',
'if',
'everything',
'were',
'right',
'wed',
'be',
'in',
'jail']
This list of words is then transformed into a list that givens the number of vowels using the function defined above. Finally the mean function is applied.
In [20]: nums = [num_vowels(word) for word in words]
In [21]: nums
Out[21]: [1, 1, 3, 2, 1, 4, 2, 2, 1, 3, 2, 1, 1, 1, 1, 2]
In [22]: mean = lambda L: sum(L)/len(L)
In [23]: average_num_vowels = mean(nums)
In [24]: average_num_vowels
Out[24]: 1.75
Finally, we generalize this process with a little refactoring.
In [25]: remove_punc = lambda s: "".join([ch.lower() for ch in s if ch not in punctuation])
In [26]: clean_and_split = lambda s: remove_punc(s).split()
In [27]: average_num_vowels = lambda s: mean([num_vowels(word) for word in clean_and_split(s)])
In [28]: average_num_vowels("Long, long ago in a galaxy far, far away.")
Out[28]: 1.3333333333333333
A second string processing pattern that is commonly applied involves
transforming one string into another. This pattern appeared in the
remove_punc function from the last example. This pattern illustrate the
process with a diagram.
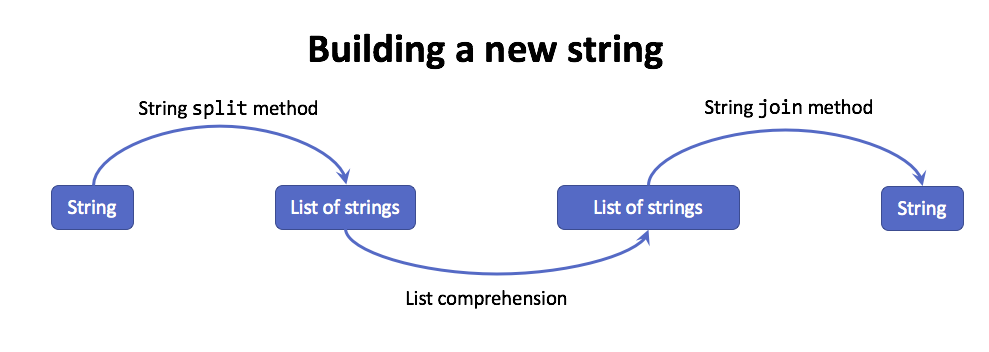
We can use list comprehensions to describe a new string, but we need to convert
the result back to a string using the str conversion function. For example,
let’s remove all of the punctuation from a string.
In [29]: zen_of_python = '''The Zen of Python, by Tim Peters
....: Beautiful is better than ugly.
....: Explicit is better than implicit.
....: Simple is better than complex.
....: Complex is better than complicated.
....: Flat is better than nested.
....: Sparse is better than dense.
....: Readability counts.
....: Special cases aren't special enough to break the rules.
....: Although practicality beats purity.
....: Errors should never pass silently.
....: Unless explicitly silenced.
....: In the face of ambiguity, refuse the temptation to guess.
....: There should be one-- and preferably only one --obvious way to do it.
....: Although that way may not be obvious at first unless you're Dutch.
....: Now is better than never.
....: Although never is often better than *right* now.
....: If the implementation is hard to explain, it's a bad idea.
....: If the implementation is easy to explain, it may be a good idea.
....: Namespaces are one honking great idea -- let's do more of those!'''
....:
In [30]: zen_list_no_punc = [ch for ch in zen_of_python if ch not in string.punctuation]
In [31]: print(zen_list_no_punc)
['T', 'h', 'e', ' ', 'Z', 'e', 'n', ' ', 'o', 'f', ' ', 'P', 'y', 't', 'h', 'o', 'n', ' ', 'b', 'y', ' ', 'T', 'i', 'm', ' ', 'P', 'e', 't', 'e', 'r', 's', '\n', 'B', 'e', 'a', 'u', 't', 'i', 'f', 'u', 'l', ' ', 'i', 's', ' ', 'b', 'e', 't', 't', 'e', 'r', ' ', 't', 'h', 'a', 'n', ' ', 'u', 'g', 'l', 'y', '\n', 'E', 'x', 'p', 'l', 'i', 'c', 'i', 't', ' ', 'i', 's', ' ', 'b', 'e', 't', 't', 'e', 'r', ' ', 't', 'h', 'a', 'n', ' ', 'i', 'm', 'p', 'l', 'i', 'c', 'i', 't', '\n', 'S', 'i', 'm', 'p', 'l', 'e', ' ', 'i', 's', ' ', 'b', 'e', 't', 't', 'e', 'r', ' ', 't', 'h', 'a', 'n', ' ', 'c', 'o', 'm', 'p', 'l', 'e', 'x', '\n', 'C', 'o', 'm', 'p', 'l', 'e', 'x', ' ', 'i', 's', ' ', 'b', 'e', 't', 't', 'e', 'r', ' ', 't', 'h', 'a', 'n', ' ', 'c', 'o', 'm', 'p', 'l', 'i', 'c', 'a', 't', 'e', 'd', '\n', 'F', 'l', 'a', 't', ' ', 'i', 's', ' ', 'b', 'e', 't', 't', 'e', 'r', ' ', 't', 'h', 'a', 'n', ' ', 'n', 'e', 's', 't', 'e', 'd', '\n', 'S', 'p', 'a', 'r', 's', 'e', ' ', 'i', 's', ' ', 'b', 'e', 't', 't', 'e', 'r', ' ', 't', 'h', 'a', 'n', ' ', 'd', 'e', 'n', 's', 'e', '\n', 'R', 'e', 'a', 'd', 'a', 'b', 'i', 'l', 'i', 't', 'y', ' ', 'c', 'o', 'u', 'n', 't', 's', '\n', 'S', 'p', 'e', 'c', 'i', 'a', 'l', ' ', 'c', 'a', 's', 'e', 's', ' ', 'a', 'r', 'e', 'n', 't', ' ', 's', 'p', 'e', 'c', 'i', 'a', 'l', ' ', 'e', 'n', 'o', 'u', 'g', 'h', ' ', 't', 'o', ' ', 'b', 'r', 'e', 'a', 'k', ' ', 't', 'h', 'e', ' ', 'r', 'u', 'l', 'e', 's', '\n', 'A', 'l', 't', 'h', 'o', 'u', 'g', 'h', ' ', 'p', 'r', 'a', 'c', 't', 'i', 'c', 'a', 'l', 'i', 't', 'y', ' ', 'b', 'e', 'a', 't', 's', ' ', 'p', 'u', 'r', 'i', 't', 'y', '\n', 'E', 'r', 'r', 'o', 'r', 's', ' ', 's', 'h', 'o', 'u', 'l', 'd', ' ', 'n', 'e', 'v', 'e', 'r', ' ', 'p', 'a', 's', 's', ' ', 's', 'i', 'l', 'e', 'n', 't', 'l', 'y', '\n', 'U', 'n', 'l', 'e', 's', 's', ' ', 'e', 'x', 'p', 'l', 'i', 'c', 'i', 't', 'l', 'y', ' ', 's', 'i', 'l', 'e', 'n', 'c', 'e', 'd', '\n', 'I', 'n', ' ', 't', 'h', 'e', ' ', 'f', 'a', 'c', 'e', ' ', 'o', 'f', ' ', 'a', 'm', 'b', 'i', 'g', 'u', 'i', 't', 'y', ' ', 'r', 'e', 'f', 'u', 's', 'e', ' ', 't', 'h', 'e', ' ', 't', 'e', 'm', 'p', 't', 'a', 't', 'i', 'o', 'n', ' ', 't', 'o', ' ', 'g', 'u', 'e', 's', 's', '\n', 'T', 'h', 'e', 'r', 'e', ' ', 's', 'h', 'o', 'u', 'l', 'd', ' ', 'b', 'e', ' ', 'o', 'n', 'e', ' ', 'a', 'n', 'd', ' ', 'p', 'r', 'e', 'f', 'e', 'r', 'a', 'b', 'l', 'y', ' ', 'o', 'n', 'l', 'y', ' ', 'o', 'n', 'e', ' ', 'o', 'b', 'v', 'i', 'o', 'u', 's', ' ', 'w', 'a', 'y', ' ', 't', 'o', ' ', 'd', 'o', ' ', 'i', 't', '\n', 'A', 'l', 't', 'h', 'o', 'u', 'g', 'h', ' ', 't', 'h', 'a', 't', ' ', 'w', 'a', 'y', ' ', 'm', 'a', 'y', ' ', 'n', 'o', 't', ' ', 'b', 'e', ' ', 'o', 'b', 'v', 'i', 'o', 'u', 's', ' ', 'a', 't', ' ', 'f', 'i', 'r', 's', 't', ' ', 'u', 'n', 'l', 'e', 's', 's', ' ', 'y', 'o', 'u', 'r', 'e', ' ', 'D', 'u', 't', 'c', 'h', '\n', 'N', 'o', 'w', ' ', 'i', 's', ' ', 'b', 'e', 't', 't', 'e', 'r', ' ', 't', 'h', 'a', 'n', ' ', 'n', 'e', 'v', 'e', 'r', '\n', 'A', 'l', 't', 'h', 'o', 'u', 'g', 'h', ' ', 'n', 'e', 'v', 'e', 'r', ' ', 'i', 's', ' ', 'o', 'f', 't', 'e', 'n', ' ', 'b', 'e', 't', 't', 'e', 'r', ' ', 't', 'h', 'a', 'n', ' ', 'r', 'i', 'g', 'h', 't', ' ', 'n', 'o', 'w', '\n', 'I', 'f', ' ', 't', 'h', 'e', ' ', 'i', 'm', 'p', 'l', 'e', 'm', 'e', 'n', 't', 'a', 't', 'i', 'o', 'n', ' ', 'i', 's', ' ', 'h', 'a', 'r', 'd', ' ', 't', 'o', ' ', 'e', 'x', 'p', 'l', 'a', 'i', 'n', ' ', 'i', 't', 's', ' ', 'a', ' ', 'b', 'a', 'd', ' ', 'i', 'd', 'e', 'a', '\n', 'I', 'f', ' ', 't', 'h', 'e', ' ', 'i', 'm', 'p', 'l', 'e', 'm', 'e', 'n', 't', 'a', 't', 'i', 'o', 'n', ' ', 'i', 's', ' ', 'e', 'a', 's', 'y', ' ', 't', 'o', ' ', 'e', 'x', 'p', 'l', 'a', 'i', 'n', ' ', 'i', 't', ' ', 'm', 'a', 'y', ' ', 'b', 'e', ' ', 'a', ' ', 'g', 'o', 'o', 'd', ' ', 'i', 'd', 'e', 'a', '\n', 'N', 'a', 'm', 'e', 's', 'p', 'a', 'c', 'e', 's', ' ', 'a', 'r', 'e', ' ', 'o', 'n', 'e', ' ', 'h', 'o', 'n', 'k', 'i', 'n', 'g', ' ', 'g', 'r', 'e', 'a', 't', ' ', 'i', 'd', 'e', 'a', ' ', ' ', 'l', 'e', 't', 's', ' ', 'd', 'o', ' ', 'm', 'o', 'r', 'e', ' ', 'o', 'f', ' ', 't', 'h', 'o', 's', 'e']
In [32]: zen_string_no_punc = ''.join(zen_list_no_punc)
In [33]: print(zen_string_no_punc)
The Zen of Python by Tim Peters
Beautiful is better than ugly
Explicit is better than implicit
Simple is better than complex
Complex is better than complicated
Flat is better than nested
Sparse is better than dense
Readability counts
Special cases arent special enough to break the rules
Although practicality beats purity
Errors should never pass silently
Unless explicitly silenced
In the face of ambiguity refuse the temptation to guess
There should be one and preferably only one obvious way to do it
Although that way may not be obvious at first unless youre Dutch
Now is better than never
Although never is often better than right now
If the implementation is hard to explain its a bad idea
If the implementation is easy to explain it may be a good idea
Namespaces are one honking great idea lets do more of those
Finally, let’s count how many of the lines in the Zen of Python start with a
vowel. Recall that we want to make everything lowercase, split the list into
pieces (this time by line using "\n"), filter out the lines that start with
a vowel, and using len to process.
First, make the list lowercase,
In [34]: zen_lower = zen_string_no_punc.lower()
then split it into lines,
In [35]: lines = zen_lower.split('\n')
In [36]: lines[:5]
Out[36]:
['the zen of python by tim peters',
'beautiful is better than ugly',
'explicit is better than implicit',
'simple is better than complex',
'complex is better than complicated']
use a comprehension to filter out the lines that start with vowels,
In [37]: lines_no_vowels = [line for line in lines if line[0] in vowels]
In [38]: lines_no_vowels[:5]
Out[38]:
['explicit is better than implicit',
'although practicality beats purity',
'errors should never pass silently',
'unless explicitly silenced',
'in the face of ambiguity refuse the temptation to guess']
and use the len function to count the result.
In [39]: num_lines = len(lines_no_vowels)
In [40]: num_lines
Out[40]: 9
Let’s combine these steps into one overall expression.
In [41]: num_lines = len([line for line in zen_string_no_punc.lower().split('\n') if line[0] in vowels])
In [42]: num_lines
Out[42]: 9
and make this into a general function.
In [43]: num_lines = lambda S: len([line for line in S.lower().split('\n') if line[0] in vowels])
In [44]: num_lines(zen_string_no_punc)
Out[44]: 9
Anytime that we create a function, we should evaluate it, looking for parts that
are overly complex. In this case, the S.lower().split('\n') is complicated.
Let’s refactor by making this a different function with a better name.
Note
You can contemplate the zen of Python anytime by executing import this.
In [45]: import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
4.2.3. Installing Project Gutenberg texts with NLTK¶
We can access a large number of freely available books using the nltk python
library. First, use conda to install/update the nltk library.
$ conda install nltk
The you will need to import and download the books from a python console.
import nltk
nltk.download()
This will open another window that can be used to download part of the nltk
module. At the very least you should download gutenberg from the Corpora
table.

Now we can access the full content of novels such as Jane Austen’s Emma.
In [1]: from nltk.corpus import gutenberg
In [2]: emma = gutenberg.raw('austen-emma.txt')
In [3]: emma[:1000]
Out[3]: "[Emma by Jane Austen 1816]\n\nVOLUME I\n\nCHAPTER I\n\n\nEmma Woodhouse, handsome, clever, and rich, with a comfortable home\nand happy disposition, seemed to unite some of the best blessings\nof existence; and had lived nearly twenty-one years in the world\nwith very little to distress or vex her.\n\nShe was the youngest of the two daughters of a most affectionate,\nindulgent father; and had, in consequence of her sister's marriage,\nbeen mistress of his house from a very early period. Her mother\nhad died too long ago for her to have more than an indistinct\nremembrance of her caresses; and her place had been supplied\nby an excellent woman as governess, who had fallen little short\nof a mother in affection.\n\nSixteen years had Miss Taylor been in Mr. Woodhouse's family,\nless as a governess than a friend, very fond of both daughters,\nbut particularly of Emma. Between _them_ it was more the intimacy\nof sisters. Even before Miss Taylor had ceased to hold the nominal\noffice of governess, the mildness o"
Once we have the novel imported into Python, it can be processed to answer questions about the text. Suppose that we want to know the average word length in Emma. First, the text is preprocessed to clean and remove unwanted characters, in this case any punctuation or whitespace. (We also make all of the text lowercase out of habit.)
In [4]: from string import punctuation, whitespace
In [5]: remove_punc = lambda s: "".join([ch for ch in s if ch not in
punctuation])
In [6]: make_lower_case = lambda s: s.lower()
...:
In [7]: fix_whitespace = lambda s: "".join([" " if ch in whitespace else ch for
ch in s])
In [8]: emma = remove_punc(make_lower_case(fix_whitespace(emma)))
In [9]: emma[:100]
Out[9]: 'emma by jane austen 1816 volume i chapter i emma woodhouse handsome
clever and rich with a comfo'
Next, the text is split into a list of words and the statistic is computed.
In [10]: emma_words = emma.split()
In [11]: mean = lambda L: sum(L)/len(L)
In [12]: average_word_length = mean([len(word) for word in emma_words])
In [13]: average_word_length
Out[13]: 4.327759895276701
Caution
We were pretty careless in our preprocessing in this example. For example, the first portion of the text should be removed and we might have given separate consideration to chapter titles.
Note
This workspace is provided for your convenience. You can use this activecode window to try out anything you like.