4.5. Common Comprehension Patterns for Tables¶
In this final section on common comprehension patterns, we look at using comprehensions to transform 2D data structures.
4.5.1. Flatten a 2D data structure¶
A 2D data structure can be flattened using two for expressions. The second
for will iterate over the rows from the first for. To flatten the
data structure, don’t include an inner comprehension.
In [1]: list_of_lists = [[1], [1, 2], [4, 5, "a"]]
In [2]: flat_list = [item for row in list_of_lists for item in row]
In [3]: flat_list
Out[3]: [1, 1, 2, 4, 5, 'a']
This pattern can take some time to get used to, but we note that it matches the imperative approach to the sample problem.
In [4]: flat_list = []
In [5]: for row in list_of_lists:
...: for item in row:
...: flat_list.append(item)
...:
In [6]: flat_list
Out[6]: [1, 1, 2, 4, 5, 'a']
The following figure illustrates this connection.
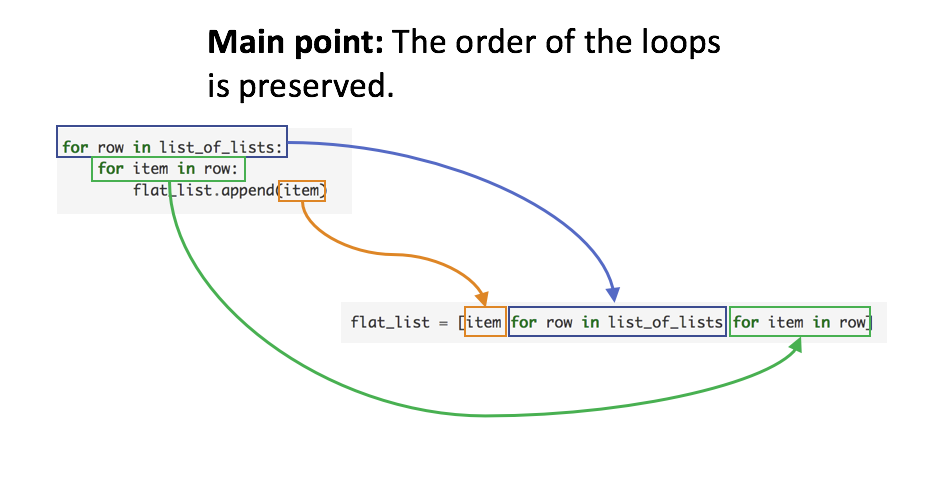
In general, readers familiar with writing imperative loops can use those patterns to transition to comprehensions.
4.5.2. Joining Tables¶
If our lists represent 2D tables of data, we can use comprehensions to join two tables, a common operation in SQL.
Note
If you don’t recall the distinctions between the different types of joins, see the first answer to this stack overflow question.
Recall that an inner-join combines all rows such that the rows match in some way. For example, if we have two lists that contain our employees hours and job title, respectively. The following program computes the inner join of these two tables when matching the employees name. Any rows for employees that don’t appear in both tables will be dropped.
In [7]: hours = [["Alice", 43],
...: ["Bob", 37],
...: ["Fred", 15]]
...:
In [8]: titles = [["Alice", "Manager"],
...: ["Betty", "Consultant"],
...: ["Bob", "Assistant"]]
...:
In [9]: inner_join = [ (nameH, ttl, hrs) for nameH, hrs in hours for nameT, ttl in titles if nameH == nameT]
In [10]: inner_join
Out[10]: [('Alice', 'Manager', 43), ('Bob', 'Assistant', 37)]
The key to joining the rows on common names is the use of the nameH ==
nameT, which guarantees that only combinations of rows where the names match
will be processes.
Check your understanding
- (A) [(10, 'zero'), (11, 'one')]
- This join will keep the second entries of the tuple when the first entries match.
- (B) [(10, 'zero'), (10, 'one'), (11, 'zero'), (11, 'one')]
- This join will keep the second entries of the tuple, but only when the first entries match.
- (C) [(10, 0), (11, 1)]
- Note that we are keeping j and w, the second entry in the respective tuples.
rec-5-52: Determine the table that will result from the following join.
t1 = [(0, 10), (1, 11)]
t2 = [(0, "zero"), (1, "one")]
[(j, w) for i, j in t1 for n, w in t2 if n == i]
The left outer join of the tables will include all of the rows from the first list, as well as the values from the second table if present. Here is the code for performing a left outer join using a list comprehension. We do this by combining the inner join with the rows that only appear in the left table.
In [11]: hours = [["Alice", 43],
....: ["Bob", 37],
....: ["Fred", 15]]
....:
In [12]: titles = [["Alice", "Manager"],
....: ["Betty", "Consultant"],
....: ["Bob", "Assistant"]]
....:
In [13]: left_names = [name for name, h in hours]
In [14]: right_names = [name for name, t in titles]
In [15]: inner_join = [ (nameH, ttl, hrs) for nameH, hrs in hours for nameT, ttl in titles if nameH == nameT]
In [16]: left_only_rows = [(name, None, hrs) for name, hrs in hours if name not in right_names]
In [17]: left_join = inner_join + left_only_rows
In [18]: left_join
Out[18]: [('Alice', 'Manager', 43), ('Bob', 'Assistant', 37), ('Fred', None, 15)]
To get the rows that are exclusive to the left table, we need to identify rows
with names that are only in the left-hand table. This is facilitated by
creating the list of names for both lists, namely left_names and
right_names, and then filtering to check that name not in right_names in
the construction of left_only_rows. As these rows are not in the right
table, and thus lack a job title, we use None to represent a missing value.
Finally, the left_only_rows are added to the inner_join rows to
construct the left_join.
You may have noticed that this approach required us to iterate through each table a number of times. This is not the most efficient implementation, and a solution that uses a relational database should be more efficient and used to larger problems, but for small problem this approach should be fine.