6.1. Reading and Writing Files¶
So far, the data we have used in this book have all been either coded right into the program, or have been entered by the user. In real life data reside in files. For example the images we worked with in the image processing unit ultimately live in files on your hard drive. Web pages, and word processing documents, and music are other examples of data that live in files. In this short chapter we will introduce the Python concepts necessary to use data from files in our programs.
6.1.1. Working with Data Files¶
For our purposes, we will assume that our data files are text files–that is, files filled with characters. The Python programs that you write are stored as text files. We can create these files in any of a number of ways. For example, we could use a text editor to type in and save the data. We could also download the data from a website and then save it in a file. Regardless of how the file is created, Python will allow us to manipulate the contents.
In Python, we must open files before we can use them and close them when we are done with them. As you might expect, once a file is opened it becomes a Python object just like all other data. Table 1 shows the functions and methods that can be used to open and close files.
| Method Name | Use | Explanation |
|---|---|---|
open |
open(filename,'r') |
Open a file called filename and use it for reading. This will return a reference to a file object. |
open |
open(filename,'w') |
Open a file called filename and use it for writing. This will also return a reference to a file object. |
close |
filevariable.close() |
File use is complete. |
6.1.2. Finding a File on your Disk¶
Opening a file requires that you, as a programmer, and Python agree about the
location of the file on your disk. The way that files are located on disk is by
their path You can think of the filename as the short name for a file, and
the path as the full name. For example on a Mac if you save the file
hello.txt in your home directory the path to that file is
/Users/yourname/hello.txt On a Windows machine the path looks a bit
different but the same principles are in use. For example on windows the path
might be C:\Users\yourname\My Documents\hello.txt
You can access files in sub-folders, also called directories, under your home
directory by adding a slash and the name of the folder. For example, if you had
a file called hello.py in a folder called CS150 that is inside a folder
called PyCharmProjects under your home directory, then the full name for the
file hello.py is /Users/yourname/PyCharmProjects/CS150/hello.py. This
is called an absolute file path. An absolute file path typically only works
on a specific computer. Think about it for a second. What other computer in the
world is going to have an absolute file path that starts with
/Users/yourname?
If a file is not in the same folder as your python program, you need to tell the
computer how to reach it. A relative file path starts from the folder that
contains your python program and follows a computer’s file hierarchy. A file
hierarchy contains folders which contains files and other sub-folders.
Specifying a sub-folder is easy – you simply specify the sub-folder’s name. To
specify a parent folder you use the special .. notation because every file
and folder has one unique parent. You can use the .. notation multiple times
in a file path to move multiple levels up a file hierarchy. Here is an example
file hierarchy that contains multiple folders, files, and sub-folders. Folders
in the diagram are displayed in bold type.
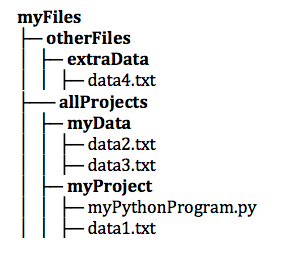
Using the example file hierarchy above, the program, myPythonProgram.py
could access each of the data files using the following relative file paths:
data1.txt../myData/data2.txt../myData/data3.txt../../otherFiles/extraData/data4.txt
Here’s the important rule to remember: If your file and your Python program are
in the same directory you can simply use the filename like this:
open('myfile.txt', 'r'). If your file and your Python program are in
different directories then you must use a relative file path to the file like
this: open('../myData/data3.txt', 'r').
6.1.3. Glossary¶
- absolute file path
- The name of a file that includes a path to the file from the root
directory of a file system. An absolute file path always starts
with a
/. - relative file path
- The name of a file that includes a path to the file from the current
working directory of a program. An relative file path never starts
with a
/.
6.1.4. Reading a File the Imperative Way¶
As an example, suppose we have a text file called qbdata.txt that contains
the following data representing statistics about NFL quarterbacks. Although it
would be possible to consider entering this data by hand each time it is used,
you can imagine that it would be time-consuming and error-prone to do this. In
addition, it is likely that there could be data from more quarterbacks and
other years. The format of the data file is as follows
First Name, Last Name, Position, Team, Completions, Attempts, Yards, TDs, Ints, Comp%, Rating
Colt McCoy QB CLE 135 222 1576 6 9 60.8% 74.5 Josh Freeman QB TB 291 474 3451 25 6 61.4% 95.9 Michael Vick QB PHI 233 372 3018 21 6 62.6% 100.2 Matt Schaub QB HOU 365 574 4370 24 12 63.6% 92.0 Philip Rivers QB SD 357 541 4710 30 13 66.0% 101.8 Matt Hasselbeck QB SEA 266 444 3001 12 17 59.9% 73.2 Jimmy Clausen QB CAR 157 299 1558 3 9 52.5% 58.4 Joe Flacco QB BAL 306 489 3622 25 10 62.6% 93.6 Kyle Orton QB DEN 293 498 3653 20 9 58.8% 87.5 Jason Campbell QB OAK 194 329 2387 13 8 59.0% 84.5 Peyton Manning QB IND 450 679 4700 33 17 66.3% 91.9 Drew Brees QB NO 448 658 4620 33 22 68.1% 90.9 Matt Ryan QB ATL 357 571 3705 28 9 62.5% 91.0 Matt Cassel QB KC 262 450 3116 27 7 58.2% 93.0 Mark Sanchez QB NYJ 278 507 3291 17 13 54.8% 75.3 Brett Favre QB MIN 217 358 2509 11 19 60.6% 69.9 David Garrard QB JAC 236 366 2734 23 15 64.5% 90.8 Eli Manning QB NYG 339 539 4002 31 25 62.9% 85.3 Carson Palmer QB CIN 362 586 3970 26 20 61.8% 82.4 Alex Smith QB SF 204 342 2370 14 10 59.6% 82.1 Chad Henne QB MIA 301 490 3301 15 19 61.4% 75.4 Tony Romo QB DAL 148 213 1605 11 7 69.5% 94.9 Jay Cutler QB CHI 261 432 3274 23 16 60.4% 86.3 Jon Kitna QB DAL 209 318 2365 16 12 65.7% 88.9 Tom Brady QB NE 324 492 3900 36 4 65.9% 111.0 Ben Roethlisberger QB PIT 240 389 3200 17 5 61.7% 97.0 Kerry Collins QB TEN 160 278 1823 14 8 57.6% 82.2 Derek Anderson QB ARI 169 327 2065 7 10 51.7% 65.9 Ryan Fitzpatrick QB BUF 255 441 3000 23 15 57.8% 81.8 Donovan McNabb QB WAS 275 472 3377 14 15 58.3% 77.1 Kevin Kolb QB PHI 115 189 1197 7 7 60.8% 76.1 Aaron Rodgers QB GB 312 475 3922 28 11 65.7% 101.2 Sam Bradford QB STL 354 590 3512 18 15 60.0% 76.5 Shaun Hill QB DET 257 416 2686 16 12 61.8% 81.3
To open this file, we would call the open function. The variable,
fileref, now holds a reference to the file object returned by
open. When we are finished with the file, we can close it by using
the close method. After the file is closed any further attempts to
use fileref will result in an error.
>>>fileref = open("qbdata.txt", "r")
>>>
>>>fileref.close()
>>>
The process of opening and closing files is very important, as the operating
system will lock write access to a file while it is open. A long-running
process that locks a file might cause problems for other processes that also
need that file. Consequently, the process of opening and closing a file should
be accomplished using the with statement, as shown below.
In [1]: with open('qbdata.txt') as f:
...: lines = [line for line in f]
...:
In [2]: lines[:5]
Out[2]:
['Colt McCoy QB CLE 135 222 1576 6 9 60.8% 74.5\n',
'Josh Freeman QB TB 291 474 3451 25 6 61.4% 95.9\n',
'Michael Vick QB PHI 233 372 3018 21 6 62.6% 100.2\n',
'Matt Schaub QB HOU 365 574 4370 24 12 63.6% 92.0\n',
'Philip Rivers QB SD 357 541 4710 30 13 66.0% 101.8\n']
Using the with statement when working with files in Python is considered
a best-practice, as it guarantees that files are properly opened and closed
at the right time.
Note
There are other uses for the with statement and it will work with any object
that supports context management. You can identify context managers by the
presence of the __enter__ and __exit__ methods.
# open is a context manager, illustrated by the existence of __enter__ and
# __exit__
In [3]: f = open('qbdata.txt')
In [4]: f.__enter__
Out[4]: <function TextIOWrapper.__enter__>
In [5]: f.__exit__
�������������������������������������������Out[5]: <function TextIOWrapper.__exit__>
The with statement assures that resources are properly managed by calling
__enter__ before, and __exit__ after, executing the block. In this case
of using open to read or write to a file, the context manager assures that
the files it opened and closed in a timely manner while hiding these details
from the user.
6.1.5. Using context managers in comprehensions¶
The with statement provides a useful abstraction for managing resources like
file input/output in imperative code.
# Proper imperative context management
In [6]: with open('qbdata.txt') as f:
...: lines = [line for line in f]
...:
In [7]: lines[:5]
Out[7]:
['Colt McCoy QB CLE 135 222 1576 6 9 60.8% 74.5\n',
'Josh Freeman QB TB 291 474 3451 25 6 61.4% 95.9\n',
'Michael Vick QB PHI 233 372 3018 21 6 62.6% 100.2\n',
'Matt Schaub QB HOU 365 574 4370 24 12 63.6% 92.0\n',
'Philip Rivers QB SD 357 541 4710 30 13 66.0% 101.8\n']
The more_itertools module provides with_iter, which
can be used to embed context managers in expressions as if they were any other
iterable object. Similar to the with statement, the with_iter will
assure that a resource is managed correctly behind the scenes.
# Proper context management in an expression/comprehension
In [8]: from more_itertools import with_iter
In [9]: lines = [line for line in with_iter(open('qbdata.txt'))]
In [10]: lines[:5]
Out[10]:
['Colt McCoy QB CLE 135 222 1576 6 9 60.8% 74.5\n',
'Josh Freeman QB TB 291 474 3451 25 6 61.4% 95.9\n',
'Michael Vick QB PHI 233 372 3018 21 6 62.6% 100.2\n',
'Matt Schaub QB HOU 365 574 4370 24 12 63.6% 92.0\n',
'Philip Rivers QB SD 357 541 4710 30 13 66.0% 101.8\n']
Using with_iter with list comprehension will be our go-to method for reading
files. Next, we look at writing data out to files.
Note
Here is a neat trick! You can install packages using pip inside the python
interpreter by importing the pip module and calling pip main. The
arguments for the call correspond to the command-line call. For example, pip
install more-itertools becomes pip.main(['install','more-itertools']).
Readers familiar with the R programming language will recognize the utility
of this approach, which is analogous to install.packages in R.
# Installing a package with pip.main
In [11]: import pip
In [12]: pip.main(['install', 'more-itertools'])
Collecting more-itertools
Using cached more_itertools-2.5.0-py3-none-any.whl
Requirement already satisfied (use --upgrade to upgrade): six<2.0.0,>=1.0.0 in /Users/tiverson/.pyenv/versions/3.5.2/envs/runestone/lib/python3.5/site-packages (from more-itertools)
Installing collected packages: more-itertools
Successfully installed more-itertools-2.5.0
6.1.6. Writing Text Files¶
One of the most commonly performed data processing tasks is to read data from a
file, manipulate it in some way, and then write the resulting data out to a new
data file to be used for other purposes later. To accomplish this, the open
function discussed above can also be used to create a new file prepared for
writing. Note in Table 1 above that the only difference
between opening a file for writing and opening a file for reading is the use of
the 'w' flag instead of the 'r' flag as the second parameter. When we
open a file for writing, a new, empty file with that name is created and made
ready to accept our data. As before, the function returns a reference to the new
file object.
Table 2 above shows one additional file method that we
have not used thus far. The write method allows us to add data to a text
file. Recall that text files contain sequences of characters. We usually think
of these character sequences as being the lines of the file where each line ends
with the newline \n character. Be very careful to notice that the write
method takes one parameter, a string. When invoked, the characters of the
string will be added to the end of the file. This means that it is the
programmers job to include the newline characters as part of the string if
desired.
As an example, consider the qbdata.txt file once again. Assume that we have
been asked to provide a file consisting of only the names of the quarterbacks.
In addition, the names should be in the order last name followed by first name
with the names separated by a comma. This is a very common type of request,
usually due to the fact that someone has a program that requires its data input
format to be different from what is available.
To construct this file, we will approach the problem using a similar algorithm
as above. We start by reading the lines into a list called lines. Then the
lines are split into rows using whitespace.
In [11]: from more_itertools import with_iter
In [12]: lines = [line for line in with_iter(open('qbdata.txt'))]
In [13]: split_line = lambda line: line.split()
In [14]: rows = [split_line(line) for line in lines]
In [15]: rows[:2]
Out[15]:
[['Colt',
'McCoy',
'QB',
'CLE',
'135',
'222',
'1576',
'6',
'9',
'60.8%',
'74.5'],
['Josh',
'Freeman',
'QB',
'TB',
'291',
'474',
'3451',
'25',
'6',
'61.4%',
'95.9']]
These lines need to be transformed into rows that contain the lastname and first
names, in that order and separated by commas. This is accomplished with two
comprehensions, first transforming the rows (list of strings) into rows (list of
strings) and then joining the rows (list of strings) into a string using the
join method with a , as the “glue.”
In [16]: names = [(row[1], row[0]) for row in rows]
In [17]: comma_separate = lambda row: ",".join(row)
In [18]: new_lines = [comma_separate(row) for row in names]
In [19]: new_lines[:5]
Out[19]: ['McCoy,Colt', 'Freeman,Josh', 'Vick,Michael', 'Schaub,Matt', 'Rivers,Philip']
When we run this program, we see the lines of output on the screen. Once we are
satisfied that it is creating the appropriate output, the next step is to add
the necessary pieces to produce an output file and write the data lines to it.
To start, we need to open a new output file by adding another with
statement, where outfile will be the alias for open("qbnames.csv",'w'),
using the 'w' flag. We can choose any file name we like. If the file does
not exist, it will be created. However, if the file does exist, it will be
reinitialized as empty and you will lose any previous contents.
Once the file has been created, we just need to call the print function
passing the file object in as a parameter. By default, the print function
will append a \n to each line. See help(print) for more information
about the optional end and sep arguments.
In [20]: with open('qbnames.csv', 'w') as outfile:
....: for line in new_lines:
....: print(line, file = outfile)
....:
The contents of the qbnames.csv file can be shown using the IPython !
magic to make a system call (to bash). In this case we pipe cat filename
through the head function to limit the output to the first 5 lines (i.e.
-n 5).
In [21]: !cat qbnames.csv | head -n 5
McCoy,Colt
Freeman,Josh
Vick,Michael
Schaub,Matt
Rivers,Philip
Note
IPython magic such as pwd, ls, and cat make working iteratively
with the file system a breeze.
6.1.7. Comprehensions and Side Effects¶
Did you notice that the last example was one of the few times that a for loop was used in this book? We could have accomplished the same outcome, writing the data to a file, using a comprehension. Why not use this approach?
Note
While we can use with_iter to read files we don’t yet have the tools
for managing an output file that doesn’t involve the with statement.
We will revisit this topic in a few chapters once we have introduced
decorator function.
Consider the following list comprehension, which mirrors the loop from the last problem.
In [22]: with open('qbnames.csv', 'w') as outfile:
....: out = [print(line, file = outfile) for line in new_lines]
....:
In [23]: out[:10]
Out[23]: [None, None, None, None, None, None, None, None, None, None]
In [24]: !cat qbnames.csv | head -n 5
����������������������������������������������������������������������McCoy,Colt
Freeman,Josh
Vick,Michael
Schaub,Matt
Rivers,Philip
Recall that print is a void function which returns nothing, i.e. None.
Consequently, the above expression produces a list of references to None,
one for each line that was written to the file. This is meaningless data!
The main theme of this text has been referentially transparent expressions, but
this last expression is at odds with this theme.
There are two alternatives to the last example that will at least return meaningful data.
6.1.8. Maintaining the sequence with do¶
First, the do function from the toolz.functoolz module takes func
and x as inputs, where func is a side-effecting function like print.
Calling do will call func with the argument x, then return x (as
opposed to the output of func(x)). Using this function in a list
comprehension will result in the output of the comprehension will result in the
output of the comprehension to be the same as the original input and this output
could then be used in later expression. Note that do only works with unary
functions, so we will need to create print_to_file to wrap the print(line,
file=outfile) call.
In [25]: from toolz.functoolz import do
In [26]: with open('qbnames.csv', 'w') as outfile:
....: print_to_file = lambda line: print(line, file = outfile)
....: out = [do(print_to_file,line) for line in new_lines]
....:
In [27]: out[:10]
Out[27]:
['McCoy,Colt',
'Freeman,Josh',
'Vick,Michael',
'Schaub,Matt',
'Rivers,Philip',
'Hasselbeck,Matt',
'Clausen,Jimmy',
'Flacco,Joe',
'Orton,Kyle',
'Campbell,Jason']
In [28]: !cat qbnames.csv | head -n 5
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������McCoy,Colt
Freeman,Josh
Vick,Michael
Schaub,Matt
Rivers,Philip
6.1.9. Abstracting mapping do onto a sequence with side_effect¶
The pattern of applying do on a unary function inside a comprehension can be
accomplished using the side_effect function from the more_itertools
module, where side_effect(print_to_file, seq) is equivalent to the following
comprehension.
[do(print_to_file, line) for line in seq]
It is important to note that side_effect, is a lazy construct that must be
forced to completion. On way to accomplish this is to wrap the call in
list, which will force completion and return the output. This approach
allows this expression to be embedded in other expressions that need this
output.
In [29]: from more_itertools import side_effect
In [30]: with open('qbnames.csv', 'w') as outfile:
....: print_to_file = lambda line: print(line, file = outfile)
....: out = list(side_effect(print_to_file, new_lines))
....:
In [31]: out[:5]
Out[31]: ['McCoy,Colt', 'Freeman,Josh', 'Vick,Michael', 'Schaub,Matt', 'Rivers,Philip']
In [32]: !cat qbnames.csv | head -n 5
����������������������������������������������������������������������������������������McCoy,Colt
Freeman,Josh
Vick,Michael
Schaub,Matt
Rivers,Philip
If, on the other hand, we do not need the output of the side_effect call,
the explicit method for throwing away this output is to use consume from
more_itertools.
In [33]: from more_itertools import side_effect, consume
In [34]: with open('qbnames.csv', 'w') as outfile:
....: print_to_file = lambda line: print(line, file = outfile)
....: consume(side_effect(print_to_file, new_lines))
....:
In [35]: !cat qbnames.csv | head -n 5
McCoy,Colt
Freeman,Josh
Vick,Michael
Schaub,Matt
Rivers,Philip
Note
This function explicitly tells the reader we are consuming a side-effect, which helps to avoid any confusion about using the output in another expression.
6.1.10. Alternative File Reading Methods¶
Again, recall the contents of the qbdata.txt file.
Colt McCoy QB CLE 135 222 1576 6 9 60.8% 74.5 Josh Freeman QB TB 291 474 3451 25 6 61.4% 95.9 Michael Vick QB PHI 233 372 3018 21 6 62.6% 100.2 Matt Schaub QB HOU 365 574 4370 24 12 63.6% 92.0 Philip Rivers QB SD 357 541 4710 30 13 66.0% 101.8 Matt Hasselbeck QB SEA 266 444 3001 12 17 59.9% 73.2 Jimmy Clausen QB CAR 157 299 1558 3 9 52.5% 58.4 Joe Flacco QB BAL 306 489 3622 25 10 62.6% 93.6 Kyle Orton QB DEN 293 498 3653 20 9 58.8% 87.5 Jason Campbell QB OAK 194 329 2387 13 8 59.0% 84.5 Peyton Manning QB IND 450 679 4700 33 17 66.3% 91.9 Drew Brees QB NO 448 658 4620 33 22 68.1% 90.9 Matt Ryan QB ATL 357 571 3705 28 9 62.5% 91.0 Matt Cassel QB KC 262 450 3116 27 7 58.2% 93.0 Mark Sanchez QB NYJ 278 507 3291 17 13 54.8% 75.3 Brett Favre QB MIN 217 358 2509 11 19 60.6% 69.9 David Garrard QB JAC 236 366 2734 23 15 64.5% 90.8 Eli Manning QB NYG 339 539 4002 31 25 62.9% 85.3 Carson Palmer QB CIN 362 586 3970 26 20 61.8% 82.4 Alex Smith QB SF 204 342 2370 14 10 59.6% 82.1 Chad Henne QB MIA 301 490 3301 15 19 61.4% 75.4 Tony Romo QB DAL 148 213 1605 11 7 69.5% 94.9 Jay Cutler QB CHI 261 432 3274 23 16 60.4% 86.3 Jon Kitna QB DAL 209 318 2365 16 12 65.7% 88.9 Tom Brady QB NE 324 492 3900 36 4 65.9% 111.0 Ben Roethlisberger QB PIT 240 389 3200 17 5 61.7% 97.0 Kerry Collins QB TEN 160 278 1823 14 8 57.6% 82.2 Derek Anderson QB ARI 169 327 2065 7 10 51.7% 65.9 Ryan Fitzpatrick QB BUF 255 441 3000 23 15 57.8% 81.8 Donovan McNabb QB WAS 275 472 3377 14 15 58.3% 77.1 Kevin Kolb QB PHI 115 189 1197 7 7 60.8% 76.1 Aaron Rodgers QB GB 312 475 3922 28 11 65.7% 101.2 Sam Bradford QB STL 354 590 3512 18 15 60.0% 76.5 Shaun Hill QB DET 257 416 2686 16 12 61.8% 81.3
In addition to using a list comprehension to read in the lines, we can simplify
this process using readline. The readlines method returns the
contents of the entire file as a list of strings, where each item in the list
represents one line of the file. It is also possible to read the entire file
into a single string with read. Table 2 summarizes
these methods and the following session shows them in action.
Note that we need to reopen the file before each read so that we start from
the beginning. Each file has a marker that denotes the current read position
in the file. Any time one of the read methods is called the marker is moved to
the character immediately following the last character returned. In the case
of readline this moves the marker to the first character of the next line
in the file. In the case of read or readlines the marker is moved to
the end of the file.
In [36]: with open("qbdata.txt", "r") as infile:
....: linelist = infile.readlines()
....:
In [37]: len(linelist)
Out[37]: 34
In [38]: linelist[0:4]
������������Out[38]:
['Colt McCoy QB CLE 135 222 1576 6 9 60.8% 74.5\n',
'Josh Freeman QB TB 291 474 3451 25 6 61.4% 95.9\n',
'Michael Vick QB PHI 233 372 3018 21 6 62.6% 100.2\n',
'Matt Schaub QB HOU 365 574 4370 24 12 63.6% 92.0\n']
| Method Name | Use | Explanation |
|---|---|---|
write |
filevar.write(astring) |
Add astring to the end of the file. filevar must refer to a file that has been opened for writing. |
read(n) |
filevar.read() |
Reads and returns a string of n
characters, or the entire file as a
single string if n is not provided. |
readline(n) |
filevar.readline() |
Returns the next line of the file with
all text up to and including the
newline character. If n is provided as
a parameter than only n characters
will be returned if the line is longer
than n. |
readlines(n) |
filevar.readlines() |
Returns a list of strings, each representing a single line of the file. If n is not provided then all lines of the file are returned. If n is provided then n characters are read but n is rounded up so that an entire line is returned. |
6.2. Importing csv files¶
The csv standard module comes with a reader function that saves us the
work of splitting each line into a list of values. The reader takes a file
object as an argument, along with a number of optional arguments like
delimiter. See the Python documentation for more
information.
Below, we import and use the csv.reader to read in qbdata.txt, using
delimiter=' ' for this space separated file.
In [39]: from csv import reader
In [40]: with open("qbdata.txt") as infile:
....: infile_reader = reader(infile, delimiter=' ')
....: table = [row for row in infile_reader]
....:
In [41]: table[:2]
Out[41]:
[['Colt',
'McCoy',
'QB',
'CLE',
'',
'135',
'222',
'1576',
'',
'',
'',
'6',
'',
'',
'9',
'',
'',
'60.8%',
'',
'',
'74.5'],
['Josh',
'Freeman',
'QB',
'TB',
'291',
'474',
'3451',
'',
'',
'',
'25',
'',
'6',
'',
'',
'61.4%',
'',
'',
'95.9']]
As you can see, space delimited files can be a problem, as the csv.reader
split at each individual space. This is due to the fact that a space separated
file is not a proper csv file. In this case, reading the lines using the string
split methods is preferrable. A better way to split data with whitespace is
to use a tab, which is represented as the special charater \t.
Let’s create a tab separated version of qbdata, titled qbdata.csv.
In [42]: with open('qbdata.txt') as infile:
....: lines = infile.readlines()
....:
In [43]: split_lines = [row.split() for row in lines]
In [44]: tab_sep_lines = ['\t'.join(row) for row in split_lines]
In [45]: with open('qbdata.csv', 'w') as outfile:
....: for line in tab_sep_lines:
....: print(line, file=outfile)
....:
In [46]: !cat qbdata.csv | head -n 5
Colt McCoy QB CLE 135 222 1576 6 9 60.8% 74.5
Josh Freeman QB TB 291 474 3451 25 6 61.4% 95.9
Michael Vick QB PHI 233 372 3018 21 6 62.6% 100.2
Matt Schaub QB HOU 365 574 4370 24 12 63.6% 92.0
Philip Rivers QB SD 357 541 4710 30 13 66.0% 101.8
Now we read the tab separated file using the csv.reader, which result in a
much cleaner representation of the data.
In [47]: from csv import reader
In [48]: with open("qbdata.csv") as infile:
....: infile_reader = reader(infile, delimiter='\t')
....: table = [row for row in infile_reader]
....:
In [49]: table[:2]
Out[49]:
[['Colt',
'McCoy',
'QB',
'CLE',
'135',
'222',
'1576',
'6',
'9',
'60.8%',
'74.5'],
['Josh',
'Freeman',
'QB',
'TB',
'291',
'474',
'3451',
'25',
'6',
'61.4%',
'95.9']]
The qbnames.csv can also be read in, and in this case, we can skip the
delimiter parameter since the default is a ,.
In [50]: with open("qbnames.csv") as infile:
....: infile_reader = reader(infile)
....: table = [row for row in infile_reader]
....:
In [51]: table[:5]
Out[51]:
[['McCoy', 'Colt'],
['Freeman', 'Josh'],
['Vick', 'Michael'],
['Schaub', 'Matt'],
['Rivers', 'Philip']]
6.3. Reading and Writing Large Files¶
There is a major advantage to using Python (e.g. versus R) to process large data files: Python can process a file line-by-line without the whole file being read into memory. R, on the other hand, reads the whole file into memory, making processing large files tricky.
A basic framework for processing a large files is to read the file, line by line, and write out the transformed data at the same time.
with open('large-infile.txt') as infile:
with open('outfile.txt') as outfile:
for old_line in infile:
new_line = process_line(old_line)
print(new_line, file=outfile)
Using thie approach, Python will make sure that only a small portion of the file will be in memory at any given time. You will practice this type of processing as part of Lab 2.